

Last time, we looked at adding or removing a handle from an active WaitForMultipleObjects, and we developed an asynchronous mechanism that requests that the changes be made soon. But asynchronous add/remove can be a problem bcause you might remove a handle, clean up the things that the handle was dependent upon, but then receive a notification that the handle you removed has been signaled, even though you already cleaned up the things the handle depended on.
What we can do is wait for the waiting thread to acknowledge the operation.
_Guarded_by_(desiredMutex) DWORD desiredCounter = 1;
DWORD activeCounter = 0;
void wait_until_active(DWORD value)
{
DWORD current = activeCounter;
while (static_cast<int>(current - value) < 0) {
WaitOnAddress(&activeCounter, ¤t,
sizeof(activeCounter), INFINITE);
current = activeCounter;
}
}
The wait_until_active function waits until the value of activeCounter is at least as large as value. We do this by subtracting the two values, to avoid wraparound problems.¹ The comparison takes advantage of the guarantee in C++20 that conversion from an unsigned integer to a signed integer converts to the value that is numerically equal modulo 2ⁿ where n is the number of bits in the destination. (Prior to C++20, the result was implementation-defined, but in practice all modern implementations did what C++20 mandates.)²
You can also use std::atomic:
_Guarded_by_(desiredMutex) DWORD desiredCounter = 1;
std::atomic<DWORD> activeCounter;
void wait_until_active(DWORD value)
{
DWORD current = activeCounter;
while (static_cast<int>(current - value) < 0) {
activeCounter.wait(current);
current = activeCounter;
}
}
As before, the background thread manipulates the desiredHandles and desiredActions, then signals the waiting thread to wake up and process the changes. But this time, the background thread blocks until the waiting thread acknowledges the changes.
// Warning: For expository purposes. Almost no error checking.
void waiting_thread()
{
bool update = true;
std::vector<wil::unique_handle> handles;
std::vector<std::function<void()>> actions;
while (true)
{
if (std::exchange(update, false)) {
std::lock_guard guard(desiredMutex);
handles.clear();
handles.reserve(desiredHandles.size() + 1);
std::transform(desiredHandles.begin(), desiredHandles.end(),
std::back_inserter(handles),
[](auto&& h) { return duplicate_handle(h.get()); });
// Add the bonus "changed" handle
handles.emplace_back(duplicate_handle(changed.get()));
actions = desiredActions;
if (activeCounter != desiredCounter) {
activeCounter = desiredCounter;
WakeByAddressAll(&activeCounter);
}
}
auto count = static_cast<DWORD>(handles.size());
auto result = WaitForMultipleObjects(count,
handles.data()->get(), FALSE, INFINITE);
auto index = result - WAIT_OBJECT_0;
if (index == count - 1) {
// the list changed. Loop back to update.
update = true;
continue;
} else if (index < count - 1) {
actions[index]();
} else {
// deal with unexpected result
}
}
}
void change_handle_list()
{
DWORD value;
{
std::lock_guard guard(desiredMutex);
⟦ make changes to desiredHandles and desiredActions ⟧
value = ++desiredCounter;
SetEvent(changed.get());
}
wait_until_active(value);
}
The pattern is that after the background thread makes the desired changes, they increment the desiredCounter and signal the event. It’s okay if multiple threads make changes before the waiting thread wakes up. The changes simply accumulate, and the event just stays signaled. Each background thread then waits for the waiting thread to process the change.
On the waiting side, we process changes as usual, but we also publish our current change counter if it has changed, to let the background threads know that we made some progress. Eventually, we will make enough progress that all of the pending changes have been processed, and the last ackground thread will be released from wait_until_active.
¹ You’ll run into problems if the counter increments 2 billion times without the worker thread noticing. At a thousand increments per second, that’ll last you a month. I figure that if you have a worker thread that is unresponsible for that long, then you have bigger problems. But you can avoid even that problem by switching to a 64-bit integer, so that the overflow won’t happen before the sun is expected to turn into a red giant.
² The holdouts would be compilers for systems that are not two’s-complement.
The post How do you add or remove a handle from an active <CODE>WaitForMultipleObjects</CODE>?, part 2 appeared first on The Old New Thing.



 Credit:
X
Credit:
X
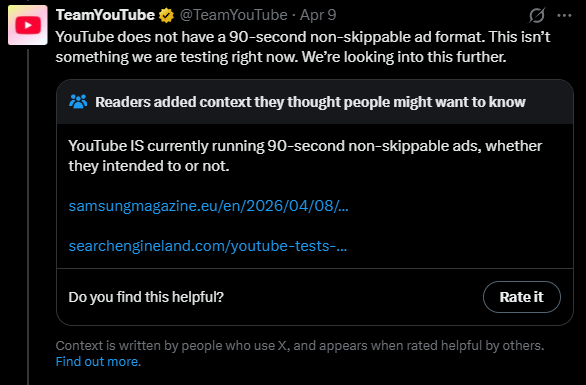
 The YouTube interface makes this look like an unskippable 90-second ad even if it's not.
Credit:
/u/Ok_Neat1652
The YouTube interface makes this look like an unskippable 90-second ad even if it's not.
Credit:
/u/Ok_Neat1652

